Shell Data Processing Pipelines
- Describe how a filter program processes standard input (
stdin) into standard output (stdout) - Interactively develop data processing pipelines using standard shell commands
- Create minimal working examples to check programs
Announcements
- The Canvas wiki looks great! Let me know if you want more pages.
- Don’t look at Discord and think, “everyone gets it except for me.” 😢 Instead, think, “Wow, there’s so much cool stuff here for me to learn!” 😁
- Beginner focused office hours after class today.
Resources
- Software Carpentry Pipes and Filters Lesson
- Wikipedia Software Filters
- Bash Redirection
Filter programs process standard input into standard output
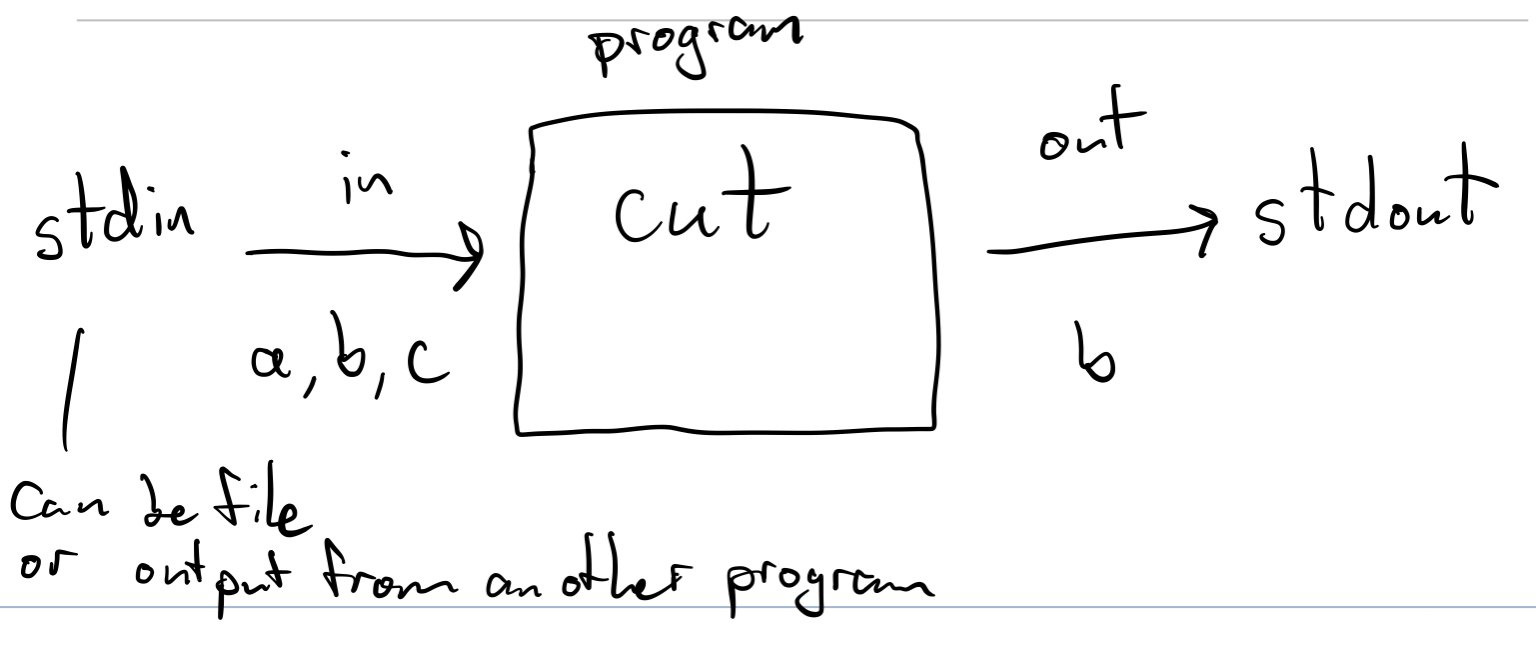
123 GO - Can filters produce more data to stdout than comes in through stdin?
Yes. We can add a novel to every line if we want.
Join two or more filters together into a pipeline
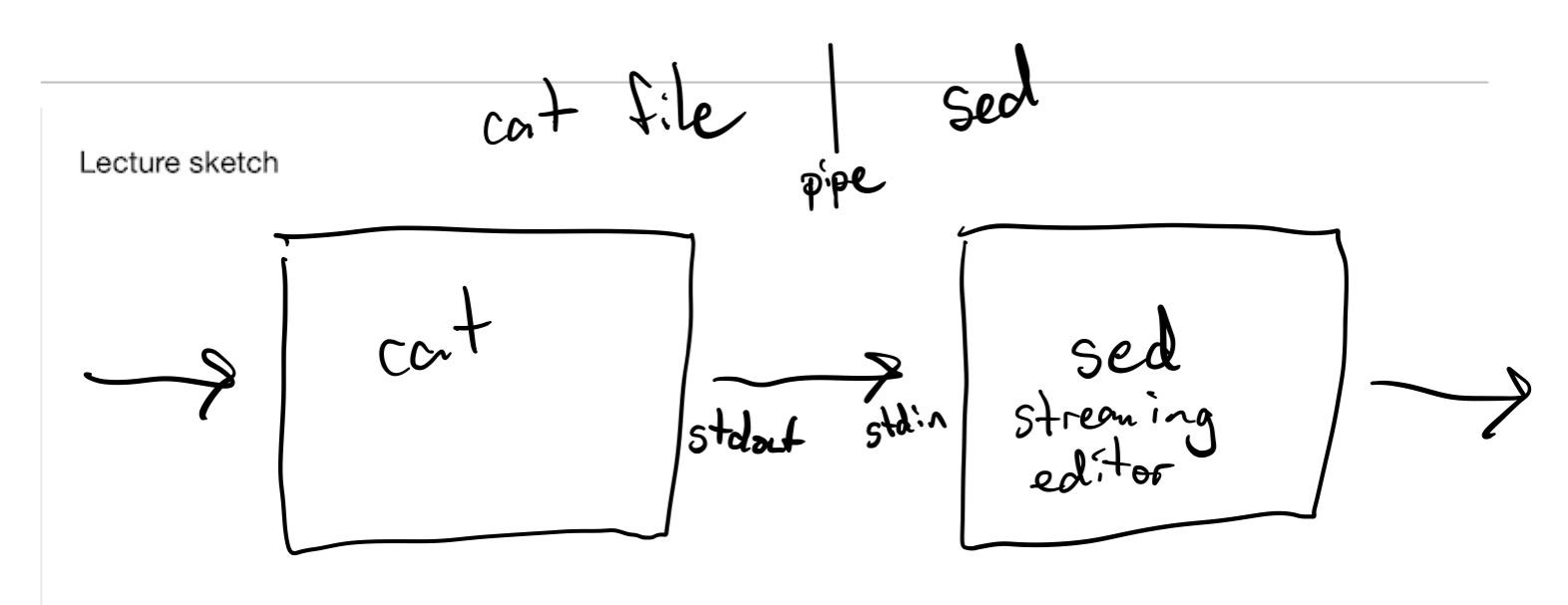
The UNIX philosophy is to take many small, specialized programs and join them together in useful ways.
123 GO - Below we have 10 commands. How many different pipelines with 5 commands can we potentially create?
10^5, since there are 10 different choices for each command, and you can repeat the same command several times. A proper subset of these pipelines make sense and are useful.
Commands
| Command | Mnemonic | Example |
|---|---|---|
cut |
cut | $ echo "1,2,3" | cut -f2 -d, cuts out the second field in 1,2,3, as separated by comma delimiters, so it prints 2. |
head |
head | $ head README prints out the first few lines in the file README. |
grep |
global regular expression print | `$ grep “clark” d |
gzip |
zip? | $ gzip README compresses the file README, saves it in the file README.gz, and deletes README |
gunzip |
unzip | $ gunzip README.gz decompresses the file README.gz, saves it in the file README, and deletes README.gz |
sed |
streaming editor | |
sort |
sort | |
tail |
tail | |
time |
time | $ time cp a.txt b.txt prints out the time required to run the command cp a.txt b.txt uniq |
uniq |
unique | $ uniq --count data.txt |
Redirection
| Command | Mnemonic | Example |
|---|---|---|
> |
overwrite | After you run $ echo "hello" > world.txt, the file world.txt will contain the single line hello. |
>> |
append | $ echo "hello" >> world.txt appends the line hello to whatever was already in world.txt. |
| |
pipe | $ echo "bac" | fold --width=1 | sort produces the sorted output lines a, b, c |
A principled approach to building shell pipelines
In this section we describe an approach to quickly and correctly developing shell pipelines. Your approach is far more important than having encyclopedic knowledge of all possible commands. This approach can also apply to other data analysis tasks.
1. Define goal
Start with a precise, explicit goal, expressed as a minimal working example. It often helps to write down in words what you are trying to do.
Here’s an example:
echo "D,bill
R,George
D,Barack
R,Donald
D,Joe" > presidents.csv
Our goal is to count up all the names that start with each letter. We want to produce a table of counts like this:
2 b
1 d
1 g
1 j
2. Read documentation
Unfortunately, options are not always portable, which means the same command might not work on two different versions of the shell.
The authoritative source on what a command does on the system that you are actually on is the manual page.
This is also known as the “man page” from the command man.
In the above example, we somehow figure out (Google?) that a program called cut might help us.
Below are the relevant parts from the manual page.
man cut
NAME
cut - remove sections from each line of files
SYNOPSIS
cut OPTION... [FILE]...
DESCRIPTION
Print selected parts of lines from each FILE to standard output.
Mandatory arguments to long options are mandatory for short options too.
-c, --characters=LIST
select only these characters
-d, --delimiter=DELIM
use DELIM instead of TAB for field delimiter
-f, --fields=LIST
select only these fields; also print any line that contains no delimiter character, unless the -s
option is specified
Use one, and only one of -b, -c or -f. Each LIST is made up of one range, or many ranges separated by
commas. Selected input is written in the same order that it is read, and is written exactly once. Each
range is one of:
N N'th byte, character or field, counted from 1
Manual page cut(1) line 1 (press h for help or q to quit)
That last line on the bottom is especially important, because it tells you how to navigate the pager that scrolls through the documentation.
The keys to navigate the file pager may seem esoteric at first, but they’re the same as Vim and less.
Use all of them together, and you will be more efficient.
Synergy!
3. Take one step at a time
Just do one thing that gets you closer to goal, and check that it does what you expected on your minimal working example before trying another step. If there are many possible steps, then pick the one that will simplify the data and the next task as much as possible.
$ cut --delimiter=, --fields=2 presidents.csv
bill
George
Barack
Donald
Joe
4. Write clear, explicit code
Use verbose options and clear formatting.
cut --delimiter=, --fields=2 presidents.csv |
cut --characters=1 |
tr [:upper:] [:lower:] |
sort |
uniq --count
The pipelines above and below are exactly equivalent, except for the way they are written. Which one is easier to explain and maintain?
cut -d, -f2 presidents.csv | cut -c1 | tr [:upper:] [:lower:] | sort | uniq -c
5. Save your work
When you do get a step that works, save it into a script file. It can also be useful to record commands you try that don’t work, as well as your thought process. For example, here are some experiments I did to explore the capabilities of aws streaming.
6. Iterate
Once you have something that minimally does what you want, try to run it on the full data set. You’ll most likely have problems, and then you’ll need to identify and fix them. Update your original minimal working example to include the problematic data.
Exercise
Setup:
echo "D,bill
R,George
D,Barack
R,Donald
D,Joe" > presidents.csv
Copy and paste your commands together with the output.
- Use
grepto find all the rows inpresidents.csvbeginning withD. Hint: you shouldn’t findR,Donald. - Write a simple pipeline with
gzipfollowed bygunzip. This is called a “round trip”, with data first being compressed, and then uncompressed. Can pipes handle binary data, in addition to text? - Use
sedto transformpresidents.csvinto the output below. Hint: an easy way to do this is to usesedtwice in a pipeline.
DEM,bill
REP,George
DEM,Barack
REP,Donald
DEM,Joe